I am taking a break from my MOOC Aggregator project to play with D3.js and some realtime data. I recently read this great blog post about performing some data analysis with python using the twitter stream and I wanted to take it another step and play with the data in realtime. So instead of dumping the data into mongodb I wanted to fill a queue in order to play with the data as it flows in. I decided to use RabbitMQ as a AMQP provider.
RabbitMQ is simple to install on a mac: brew install rabbitmq. This installs the queue and some more common plugins. See the RabbitMQ installation page for help installing on other systems. Once it was installed I started it up with the rabbitmq-server command.
Now I am ready to feed data into my queue. For this I used Daniel Forsyth's example that grabs a topic from the twitter stream and stores it into mongodb.I replaced the mongo code with activemq code. I used Pika for the python AMQP client. Here is my modified feed consumer:
import tweepy
import sys
import pika
import json
import time
#get your own twitter credentials at dev.twitter.com
consumer_key = ""
consumer_secret = ""
access_token = ""
access_token_secret = ""
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
class CustomStreamListener(tweepy.StreamListener):
def __init__(self, api):
self.api = api
super(tweepy.StreamListener, self).__init__()
#setup rabbitMQ Connection
connection = pika.BlockingConnection(
pika.ConnectionParameters(host='localhost')
)
self.channel = connection.channel()
#set max queue size
args = {"x-max-length": 2000}
self.channel.queue_declare(queue='twitter_topic_feed', arguments=args)
def on_status(self, status):
print status.text, "\n"
data = {}
data['text'] = status.text
data['created_at'] = time.mktime(status.created_at.timetuple())
data['geo'] = status.geo
data['source'] = status.source
#queue the tweet
self.channel.basic_publish(exchange='',
routing_key='twitter_topic_feed',
body=json.dumps(data))
def on_error(self, status_code):
print >> sys.stderr, 'Encountered error with status code:', status_code
return True # Don't kill the stream
def on_timeout(self):
print >> sys.stderr, 'Timeout...'
return True # Don't kill the stream
sapi = tweepy.streaming.Stream(auth, CustomStreamListener(api))
# my keyword today is chelsea as the team just had a big win
sapi.filter(track=['chelsea'])
Note: I set the queue size to 2000 tweets.
After running this script you start to see the tweets streaming in and filling the queue:
(twitter_feed_cloud)[brett:~/src/twitter_feed_cloud]$ python feed_producer.py
chelsea better not park the bus again
Kick Off babak pertama, Chelsea vs Atletico Madrid #UCL
Chelsea / atletico madrid #CestPartie
Pegang Chelsea Aja dah
Chelsea vs Atletico! Kick off..
Here is the rabbitMQ screenshot:
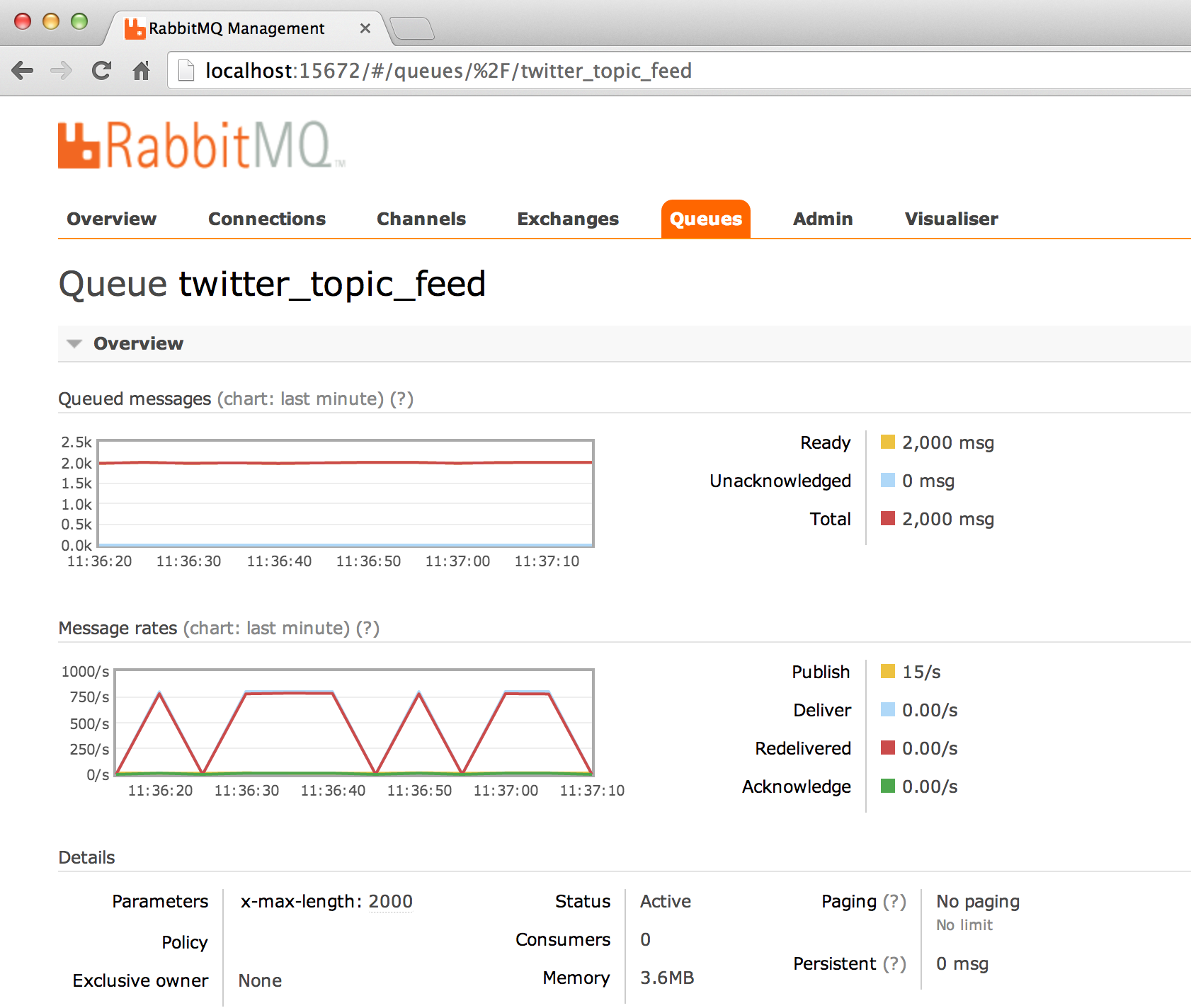
Consuming the queue
Now that I have realtime data flowing into a RabbitMQ queue I can start to play with the data. At this point I wasn't quite sure what I wanted to do with the data other than play with some d3 charts. The first thing I needed to do was stand up an API that will send the data to the frontend via AJAX (at least initially).
One thing I knew I wanted to do was aggregate and count words in the tweets. So I used Flask to standup a quick API that consumes the queue, formats the data, and sends JSON payloads to the frontend. Consuming the queue is pretty easy with Pika:
import pika
#setup queue
connection = pika.BlockingConnection()
channel = connection.channel()
#function to get X messages from the queue
def get_tweets(size=10):
tweets = []
count = 0
for method_frame, properties, body in channel.consume('twitter_topic_feed'):
tweets.append(json.loads(body))
count += 1
# Acknowledge the message
channel.basic_ack(method_frame.delivery_tag)
# Escape out of the loop after 10 messages
if count == size:
break
# Cancel the consumer and return any pending messages
requeued_messages = channel.cancel()
print 'Requeued %i messages' % requeued_messages
return tweets
Here is the full Flask API with a route to get the word counts from X number of tweets:
from flask import Flask, Response
import pika
import json
import pandas
#setup queue
connection = pika.BlockingConnection()
channel = connection.channel()
#function to get data from queue
def get_tweets(size=10):
tweets = []
# Get ten messages and break out
count = 0
for method_frame, properties, body in channel.consume('twitter_topic_feed'):
tweets.append(json.loads(body))
count += 1
# Acknowledge the message
channel.basic_ack(method_frame.delivery_tag)
# Escape out of the loop after 10 messages
if count == size:
break
# Cancel the consumer and return any pending messages
requeued_messages = channel.cancel()
print 'Requeued %i messages' % requeued_messages
return tweets
app = Flask(__name__)
app.config.update(
DEBUG=True,
PROPAGATE_EXCEPTIONS=True
)
@app.route('/feed/raw_feed', methods=['GET'])
def get_raw_tweets():
tweets = get_tweets(size=5)
text = ""
for tweet in tweets:
tt = tweet.get('text', "")
text = text + tt + "<br>"
return text
@app.route('/feed/word_count', methods=['GET'])
def get_word_count():
#get tweets from the queue
tweets = get_tweets(size=30)
#dont count these words
ignore_words = [ "rt", "chelsea"]
words = []
for tweet in tweets:
tt = tweet.get('text', "").lower()
for word in tt.split():
if "http" in word:
continue
if word not in ignore_words:
words.append(word)
p = pandas.Series(words)
#get the counts per word
freq = p.value_counts()
#how many max words do we want to give back
freq = freq.ix[0:300]
response = Response(freq.to_json())
response.headers.add('Access-Control-Allow-Origin', "*")
return response
if __name__ == "__main__":
app.run()
You will want to tune this to only process a number of tweets based on your polling rate and the rate of messages coming from twitter. With the Chelsea topic I was getting about 25 tweets per second and polling this api every 3 seconds. I set the number of tweets per request to 30. I also set the number of words to give back to 300.
Here is the curl response:
GET http://localhost:5000/feed/word_count --json
HTTP/1.0 200 OK
Access-Control-Allow-Origin: *
Content-Length: 96
Content-Type: text/html; charset=utf-8
Date: Wed, 30 Apr 2014 19:21:20 GMT
Server: Werkzeug/0.9.4 Python/2.7.6
{"de":8,"la":6,"atl\u00e9tico":6,"el":4,"madrid":4,"y":4,"vs":3,"masih":3,"champions":3,"0-0":3}
Creating an animated word cloud
Now we can use this API to feed some cool frontend visualizations. I have wanted to play with D3 more and I found a word cloud D3 implementation (not that I believe word clouds are really interesting, but they look cool). This word cloud has a useful example in the examples folder that gave me a starting point. However, I wanted my word cloud to be bigger and to be animated with real time data.
The first step was to create my word_cloud object:
var fontSize = d3.scale.log().range([10, 90]);
//create my cloud object
var mycloud = d3.layout.cloud().size([600, 600])
.words([])
.padding(2)
.rotate(function() { return ~~(Math.random() * 2) * 90; })
.font("Impact")
.fontSize(function(d) { return fontSize(d.size); })
.on("end", draw)
Here I have a cloud object that is 600x600 pixels and it will place text that is rotated either 0 or 90 degrees. This cloud also changes the font-size based on the size parameter passed in and it will use D3's scaling feature to scale the size to a value between 10px and 90px. I planned to use the word count value as the size parameter. Now we also need the draw function that actually renders the SVG graphic on screen.
Here is my draw function:
//render the cloud with animations
function draw(words) {
//render new tag cloud
d3.select("body").selectAll("svg")
.append("g")
.attr("transform", "translate(300,300)")
.selectAll("text")
.data(words)
.enter().append("text")
.style("font-size", function(d) { return ((d.size)* 1) + "px"; })
.style("font-family", "Impact")
.style("fill", function(d, i) { return fill(i); })
.style("opacity", 1e-6)
.attr("text-anchor", "middle")
.attr("transform", function(d) { return "translate(" + [d.x, d.y] + ")rotate(" + d.rotate + ")"; })
.transition()
.duration(1000)
.style("opacity", 1)
.text(function(d) { return d.text; });
Here I am creating a new svg group for each set of words. The .append("g").attr("transform", "translate(300,300)") line gives the starting point for every word. The word cloud tries to place a word at this position and moves it outward if it intersects other words. I also added a animation to fade the words in once they are all created. That animation is handled by .transition().duration(1000).style("opacity", 1).
Now I want to dynamically grab the words from my api. Here is the function that gets the words from the flask API and pushes them into my tag cloud and then renders it.
//ajax call
function get_words() {
//make ajax call
d3.json("http://127.0.0.1:5000/feed/word_count", function(json, error) {
if (error) return console.warn(error);
var words_array = [];
for (key in json){
words_array.push({text: key, size: json[key]})
}
//render cloud
mycloud.stop().words(words_array).start();
});
};
This creates this cool tag cloud:
Now I want to poll for new data every X seconds based on how fast data is coming in from my feed. Here I have it set to a four second interval. var interval = setInterval(function(){get_words()}, 4000);
Here is the animated version:
My final javascript word count implementation:
<!DOCTYPE html>
<meta charset="utf-8">
<body>
<script src="d3-cloud/lib/d3/d3.js"></script>
<script src="d3-cloud/d3.layout.cloud.js"></script>
<script>
(function() {
var fill = d3.scale.category20();
//what range of font sizes do we want, we will scale the word counts
var fontSize = d3.scale.log().range([10, 90]);
//create my cloud object
var mycloud = d3.layout.cloud().size([600, 600])
.words([])
.padding(2)
.rotate(function() { return ~~(Math.random() * 2) * 90; })
// .rotate(function() { return 0; })
.font("Impact")
.fontSize(function(d) { return fontSize(d.size); })
.on("end", draw)
//render the cloud with animations
function draw(words) {
//fade existing tag cloud out
d3.select("body").selectAll("svg").selectAll("g")
.transition()
.duration(1000)
.style("opacity", 1e-6)
.remove();
//render new tag cloud
d3.select("body").selectAll("svg")
.append("g")
.attr("transform", "translate(300,300)")
.selectAll("text")
.data(words)
.enter().append("text")
.style("font-size", function(d) { return ((d.size)* 1) + "px"; })
.style("font-family", "Impact")
.style("fill", function(d, i) { return fill(i); })
.style("opacity", 1e-6)
.attr("text-anchor", "middle")
.attr("transform", function(d) { return "translate(" + [d.x, d.y] + ")rotate(" + d.rotate + ")"; })
.transition()
.duration(1000)
.style("opacity", 1)
.text(function(d) { return d.text; });
}
//ajax call
function get_words() {
//make ajax call
d3.json("http://127.0.0.1:5000/feed/word_count", function(json, error) {
if (error) return console.warn(error);
var words_array = [];
for (key in json){
words_array.push({text: key, size: json[key]})
}
//render cloud
mycloud.stop().words(words_array).start();
});
};
//create SVG container
d3.select("body").append("svg")
.attr("width", 600)
.attr("height", 600);
//render first cloud
get_words();
//start streaming
//var interval = setInterval(function(){get_words()}, 4000);
})();
</script>
What's Next?
- Use Node.js and socket.io to push the data to the client instead of polling it. I can use a node.js AMQP client to grab data off the queue.
- Create other cool visualizations. Maybe a realtime geo location map or a animated chart showing client usage shares.
- Any other cool ideas? Comment below.